From scratch model part 2: training an image recognition model using fastai
image recognition
CNN
fastai
Author
Mike Gallimore
Published
February 8, 2023
In this presentation Mike walked us through how to train an image classifier using the fastai library. This was a group coding session from no-code to a working model.
Running a model on GPU in Jupyter Notebook.
Most of this notebook is adapted from the fast.ai course material, link here
Notebook Tips
type ? or ?? next to a function then shift + return to execute the cell to get the source code.
Press shift + tab inside function’s parentheses to get function signature and docstring
Type the name of a module and hit enter to get info about its type and location.
Requirement already satisfied: duckduckgo_search in /usr/local/lib/python3.9/dist-packages (2.8.0)
Requirement already satisfied: requests>=2.28.1 in /usr/local/lib/python3.9/dist-packages (from duckduckgo_search) (2.28.1)
Requirement already satisfied: click>=8.1.3 in /usr/local/lib/python3.9/dist-packages (from duckduckgo_search) (8.1.3)
Requirement already satisfied: idna<4,>=2.5 in /usr/lib/python3/dist-packages (from requests>=2.28.1->duckduckgo_search) (2.8)
Requirement already satisfied: charset-normalizer<3,>=2 in /usr/local/lib/python3.9/dist-packages (from requests>=2.28.1->duckduckgo_search) (2.1.0)
Requirement already satisfied: certifi>=2017.4.17 in /usr/lib/python3/dist-packages (from requests>=2.28.1->duckduckgo_search) (2019.11.28)
Requirement already satisfied: urllib3<1.27,>=1.21.1 in /usr/local/lib/python3.9/dist-packages (from requests>=2.28.1->duckduckgo_search) (1.26.10)
WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv
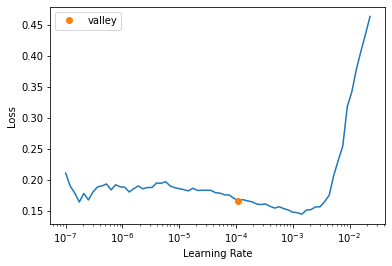
If the device type is ‘cuda’ that means we’ve got the model on the GPU. If device type is ‘cpu’ then now’s a good time to see if there is a free GPU instance available. The data you downloaded earlier won’t be lost since Paperspace has persistent storage.
# Docs for some modules. Uncomment as required. # DataLoader?# DataLoaders?# Datasets?# torch.utils.data.Dataset?# torch.utils.data.DataLoader?
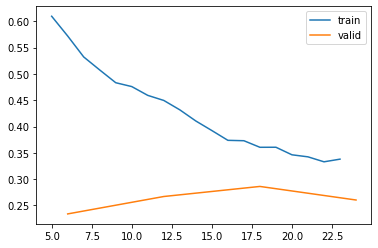
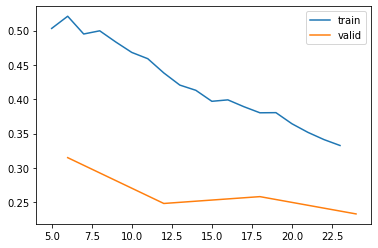
Training and validation sets
Our data is split into training and validation batches. 20% of the data is in the validation set, and 80% is in the training set.
Dataset: an iterable over tuples containing images with their corresponding category. DataLoader: a PyTorch iterable returning a batch of datasets. DataLoaders: a fastai iterable which splits dataloaders into training and validation datasets.
Upload some images to the images folder of your GPU instance. Make sure the images weren’t in the training set.
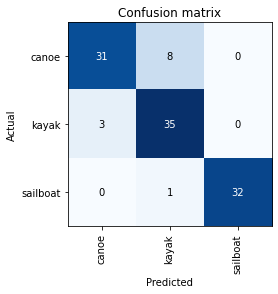
See how well your model does at differentiating between different images. I’ve uploaded some of my own photos to test.